- How to Extract Domain from URL in Pandas
- Setup
- Step 1: Extract domain from URL — urlparse
- Step 2: Extract domain from URL — regex
- Conclusion
- Extract Domain From URL in Python
- Method 1: Using the tldextract package
- Example
- Another example
- Method 2: Using tld module
- Example
- Another example
- Extracting Domain Name from a URL in Python
- Components of a URL
- Why is a domain name important?
- Extracting Domain Names from URL in Python
- Conclusion
- Extract Domain From URL in Python
- Use urlparse() to Extract Domain From the URL
- Related Article — Python URL
How to Extract Domain from URL in Pandas
In this short guide, I’ll show you how to extract domain from a URL column in Pandas DataFrame. You can also find how to extract netloc, schema, path, params. So at the end you will get:
['https://www.datascientyst.com/cheatsheet','https://www.softhints.com/python'] 0 (https, www.datascientyst.com, /cheatsheet, , , ) 1 (https, www.softhints.com, /python, , , ) Name: urls, dtype: object or extracting only domains:
0 www.datascientyst.com 1 www.softhints.com Name: urls, dtype: object Setup
Let’s have DataFrame with URL column from which we will extract list of domains:
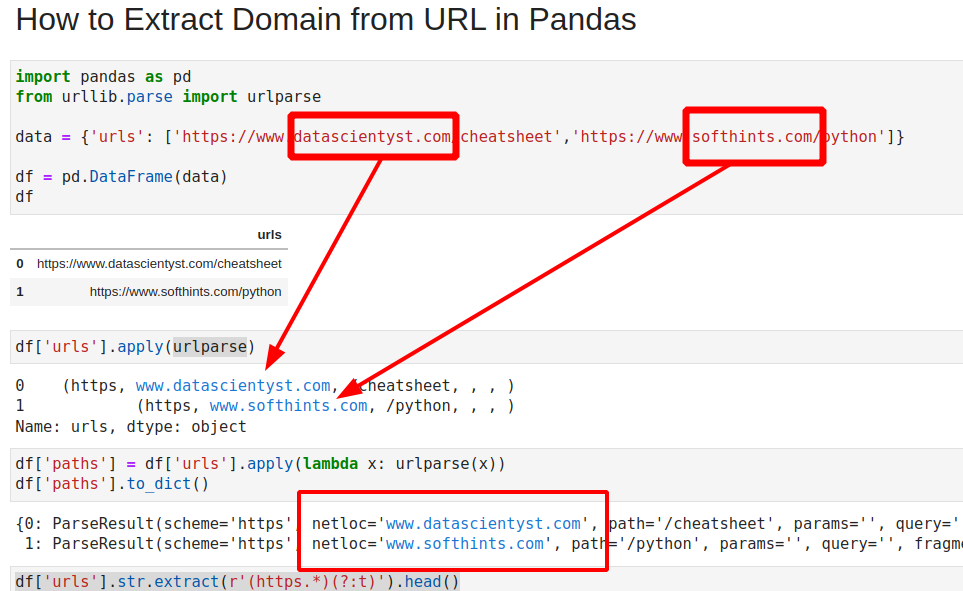
import pandas as pd data = df = pd.DataFrame(data) | urls | |
|---|---|
| 0 | https://www.datascientyst.com/cheatsheet |
| 1 | https://www.softhints.com/python |
Step 1: Extract domain from URL — urlparse
First way to extract domain from URL in Python is library — urlparse :
from urllib.parse import urlparse df['urls'].apply(urlparse) This will extract all information as Series of tuples:
0 (https, www.datascientyst.com, /cheatsheet, , , ) 1 (https, www.softhints.com, /python, , , ) Name: urls, dtype: object To extract only the netloc or the domain we can use:
df['urls'].apply(lambda x: urlparse(x)[1]) extracted netloc-s from the URL column:
0 www.datascientyst.com 1 www.softhints.com Name: urls, dtype: object We can extract the full ParseResult from the urlparse library by:
df['paths'] = df['urls'].apply(lambda x: urlparse(x)) df['paths'].to_dict() result is full URL information:
Step 2: Extract domain from URL — regex
We can use regular expression in order to extract patterns from the URL columns. Pandas offers .str.extract method:
would extract the domains plus the subdomains if any:
| 0 | |
|---|---|
| 0 | www.datascientyst.com |
| 1 | www.softhints.com |
Or we can match up to symbol without extracting the symbol. In this case we will search for anything until we match char t :
df['urls'].str.extract(r'(https.*)(?:t)').head() | 0 | |
|---|---|
| 0 | https://www.datascientyst.com/cheatshee |
| 1 | https://www.softhints.com/py |
Conclusion
We saw two different ways how to parse URL information with Python and Pandas.
We can extract from Pandas DataFrame information like:
- scheme=’https’
- netloc=’www.datascientyst.com’
- path=’/cheatsheet’
- params=»
- query=»
- fragment=»
By using DataScientYst — Data Science Simplified, you agree to our Cookie Policy.
Extract Domain From URL in Python
The Figure shown below shows the main parts of the URL. In this article, we will explore methods that can be used to extract the Domain from the URL in Python.

There are three tools/packages/methods we will use to accomplish this:
- Method 1. Using the tldextract module,
- Method 2: Using tld library and,
- Method 2: urlparse() in urllib.parse.
The first two methods depend on Public Suffix List (PSL), whereas urllib takes the generic approach.
Method 1: Using the tldextract package
The package does not come pre-installed with Python. For that reason, you might have to install it before using it. You can do that by running the following command on the terminal:
The package separates a URL’s Subdomain, Domain, and public suffix (TLD), using the Public Suffix List (PSL).
Example
ExtractResult(subdomain='forums.news', domain='cnn', suffix='com') ExtractResult(subdomain='forums', domain='bbc', suffix='co.uk') ExtractResult(subdomain='www', domain='worldbank', suffix='org.kg') cnn bbc worldbank
Another example
urls = [ «http://asciimath.org/» , «https://todoist.com/app/today» , «http://forums.news.cnn.com/» , «http://forums.bbc.co.uk/» , «https://www.amazon.de/» , «https://google.com/» , «http://www.example.test/foo/bar» , «https://sandbox.evernote.com/Home.action» ]
Parts: ExtractResult(subdomain='', domain='asciimath', suffix='org') --> Domain: asciimath Parts: ExtractResult(subdomain='', domain='todoist', suffix='com') --> Domain: todoist Parts: ExtractResult(subdomain='forums.news', domain='cnn', suffix='com') --> Domain: cnn Parts: ExtractResult(subdomain='forums', domain='bbc', suffix='co.uk') --> Domain: bbc Parts: ExtractResult(subdomain='www', domain='amazon', suffix='de') --> Domain: amazon Parts: ExtractResult(subdomain='', domain='google', suffix='com') --> Domain: google Parts: ExtractResult(subdomain='www.example', domain='test', suffix='') --> Domain: test Parts: ExtractResult(subdomain='sandbox', domain='evernote', suffix='com') --> Domain: evernote
Method 2: Using tld module
Extracts the Top-Level Domain (TLD) from the URL given. The list of TLD names is taken from Public Suffix. You can install tld with pip using the command “pip install tld”.
Optionally raises exceptions on non-existing TLDs or silently fails (if fail_silently argument is set to True)
Note: The module requires Python 2.7, 3.5, 3.6, 3.7, 3.8, and 3.9.
Example
Respond of get_tld() TLD: co.uk Subdomain: forums Domain: bbc Top Level Domain: co.uk Full-level Domain: bbc.co.uk
If you try to get the parts of a URL not in Public Suffix List (PSL), tld will through TldDomainNotFound Exception unless fail_silently is set to True (in this case, None is returned). For example,
tld.exceptions.TldDomainNotFound: Domain www.example.test didn't match any existing TLD name!
Another example
from tld import get_tld urls = ["http://asciimath.org/", "https://todoist.com/app/today", "http://forums.news.cnn.com/", "http://forums.bbc.co.uk/", "https://www.amazon.de/", "https://google.com/", "http://www.example.test/foo/bar", "https://sandbox.evernote.com/Home.action", ] for url in urls: response = get_tld(url, as_object=True, fail_silently=True) if response is not None: # this captures URL domains not in the Public Suffix List (PSL) # Get the full Domain - subdomain + domain print("Full Domain: ", response.fld,"--> Domain: ", response.domain, "--> URL: ", url) else: print(f"The URL is not in the Public Suffix List (PSL).") Full Domain: asciimath.org --> Domain: asciimath --> URL: http://asciimath.org/ Full Domain: todoist.com --> Domain: todoist --> URL: https://todoist.com/app/today Full Domain: cnn.com --> Domain: cnn --> URL: http://forums.news.cnn.com/ Full Domain: bbc.co.uk --> Domain: bbc --> URL: http://forums.bbc.co.uk/ Full Domain: amazon.de --> Domain: amazon --> URL: https://www.amazon.de/ Full Domain: google.com --> Domain: google --> URL: https://google.com/ The URL http://www.example.test/foo/bar is not in the Public Suffix List. Full Domain: evernote.com --> Domain: evernote --> URL: https://sandbox.evernote.com/Home.action
Extracting Domain Name from a URL in Python

A URL or a uniform resource locator is nothing but a web address. It is used for locating resources on computer networks, mainly the world wide web.
A web address is the address on the web which contains various parts in it. Just like a normal address which consists of many different parts such as house number, street name, etc. a web address is also composed of various portions.
The domain name is one such portion of an URL. The domain name is essentially the name of the website which helps in locating the content we look at on the internet. The largest domain of all is the world wide web. Every website on the web is therefore a domain.
An URL is a link that you can click on webpages or in any other software. You can also type it directly into your web browser and visit.
Components of a URL
Let’s dive deeper into the various components of a URL and understand their significance. A web address or a URL can be broken down into smaller chunks and they are as follows:
- The protocol: This is the first part of an URL. Protocols can be of the HTTP(hypertext transfer protocol) type, HTTPS(hypertext transfer protocol secured) type, this is more secure than the previous one or FTP(file transfer protocol) type.
- A colonfollowed by two forward slashes.
- The domain:The domain name can be subdivided into three parts as well. They are:
- Subdomain: It specifies the page of a website. This enables search engines to visit different pages of your website. If there is only one main page in that website, it can be “www” as well.
- Domain Name: This is the main name of your website. This is the domain name of your website. In this article we will learn how to extract this domain name from an URL in python.
- Suffix: This refers to the type of website you have. For example, organizations may use “.org” and companies mostly use “.com”.
This is the basic structure of an URL on the world wide web, there may be added elements such as port numbers or paths in it which will ultimately take you to your desired location. Since we will learn how to extract a domain name in this tutorial, it can be done regardless of the structure of an URL.

Why is a domain name important?
A domain name not only makes your company or website stand out, it adds credibility to your business. This is why domain names are rarely free and you have to pay in order to obtain a domain to your name.
A good domain name will attract traffic to your webpage and will add legitimacy to your work. An attractive domain name is easy to remember and in the long run might even become a brand in itself in e-commerce.
There are many paid services that can extract the domain name from an URL on the internet. But let’s see how we can do it for free using python in the next section.
Extracting Domain Names from URL in Python
The tldextract library is utilized to extract the domain name from a URL using Python. By installing the library using pip and importing it into your script, you can use the extract() function to find the domain name of any given URL
Run the following in your command prompt. Use it in administrator mode during installation to avoid PATH conflicts.
The tldextract is an in-built python library that extracts the different parts of an URL such as the domain name, subdomains, public suffixes etc. It contains the extract() function which is a namedtuple which makes accessing the separate parts easier. Read more about it here.
The following will extract the domain name from your URL.
import tldextract # Get URL from user url = input("Enter URL: ") # Extract information from URL extracted_info = tldextract.extract(url) # Print all extracted information print("The result after extraction is:", extracted_info) # Print only the domain name print("Domain name is:", extracted_info.domain)Enter URL= https://www.askpython.com/ The result after extraction is: ExtractResult(subdomain='www', domain='askpython', suffix='com') Domain name is: askpython
Conclusion
Now you have a clear understanding of URLs and their components, including the importance of domain names for credibility and branding. By leveraging Python and the tldextract library, you can easily extract domain names from URLs without relying on paid services. This opens up new opportunities for analyzing and working with web addresses in your projects.
Extract Domain From URL in Python

This article will use practical examples to explain Python’s urlparse() function to parse and extract the domain name from a URL. We’ll also discuss improving our ability to resolve URLs and use their different components.
Use urlparse() to Extract Domain From the URL
The urlparse() method is part of Python’s urllib module, useful when you need to split the URLs into different components and use them for various purposes. Let us look at the example:
from urllib.parse import urlparse component = urlparse('http://www.google.com/doodles/mothers-day-2021-april-07') print(component)In this code snippet, we have first included the library files from the urllib module. Then we passed a URL to the urlparse function. The return value of this function is an object that acts like an array having six elements that are listed below:
- scheme — Specify the protocol we can use to get the online resources, for instance, HTTP / HTTPS .
- netloc — net means network and loc means location; so it means URLs’ network location.
- path — A specific pathway a web browser uses to access the provided resources.
- params — These are the path elements’ parameters.
- query — Adheres to the path component & the data’s steam that a resource can use.
- fragment — It classifies the part.
When we display this object using the print function, it will print its components’ value. The output of the above code fence will be as follows:
ParseResult(scheme='http', netloc='www.google.com', path='/doodles/mothers-day-2021-april-07', params='', query='', fragment='')You can see from the output that all the URL components are separated and stored as individual elements in the object. We can get the value of any component by using its name like this:
from urllib.parse import urlparse domain_name = urlparse('http://www.google.com/doodles/mothers-day-2021-april-07').netloc print(domain_name)Using the netloc component, we can get the domain name of the URL as follows:
This way, we can get our URL parsed and use its different components for various purposes in our programming.
Related Article — Python URL
Copyright © 2023. All right reserved


