- Python: Работа с базой данных, часть 1/2: Используем DB-API
- Готовим инвентарь для дальнейшей комфортной работы
- Python DB-API модули в зависимости от базы данных
- Соединение с базой, получение курсора
- Чтение из базы
- Запись в базу
- Разбиваем запрос на несколько строк в тройных кавычках
- Объединяем запросы к базе данных в один вызов метода
- Делаем подстановку значения в запрос
- Делаем множественную вставку строк проходя по коллекции с помощью метода курсора .executemany()
- Получаем результаты по одному, используя метод курсора .fetchone()
- Курсор как итератор
- UPD: Повышаем устойчивость кода
- UPD: Использование with в psycopg2
- UPD: Ипользование row_factory
- Дополнительные материалы (на английском)
- Приглашаю к обсуждению:
- How to Execute SQL Queries in Python and R Tutorial
- What is SQL
- Why use SQL with Python and R?
- Python Tutorial
- Setting Up
Python: Работа с базой данных, часть 1/2: Используем DB-API
Python DB-API – это не конкретная библиотека, а набор правил, которым подчиняются отдельные модули, реализующие работу с конкретными базами данных. Отдельные нюансы реализации для разных баз могут отличаться, но общие принципы позволяют использовать один и тот же подход при работе с разными базами данных.
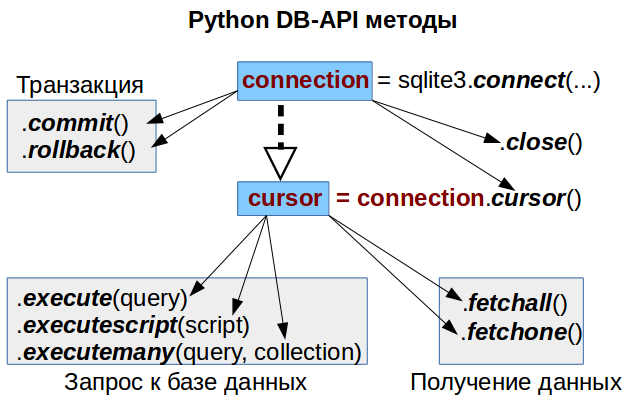
В статье рассмотрены основные методы DB-API, позволяющие полноценно работать с базой данных. Полный список можете найти по ссылкам в конец статьи.
Требуемый уровень подготовки: базовое понимание синтаксиса SQL и Python.
Готовим инвентарь для дальнейшей комфортной работы
- Python имеет встроенную поддержку SQLite базы данных, для этого вам не надо ничего дополнительно устанавливать, достаточно в скрипте указать импорт стандартной библиотеки
Примечание: внося изменения в базу не забудьте их применить, так как база с непримененными изменениями остается залоченной.
Вы можете использовать (последние два варианта кросс-платформенные и бесплатные):
Python DB-API модули в зависимости от базы данных
Соединение с базой, получение курсора
Для начала рассмотрим самый базовый шаблон DB-API, который будем использовать во всех дальнейших примерах:
# Импортируем библиотеку, соответствующую типу нашей базы данных import sqlite3 # Создаем соединение с нашей базой данных # В нашем примере у нас это просто файл базы conn = sqlite3.connect('Chinook_Sqlite.sqlite') # Создаем курсор - это специальный объект который делает запросы и получает их результаты cursor = conn.cursor() # ТУТ БУДЕТ НАШ КОД РАБОТЫ С БАЗОЙ ДАННЫХ # КОД ДАЛЬНЕЙШИХ ПРИМЕРОВ ВСТАВЛЯТЬ В ЭТО МЕСТО # Не забываем закрыть соединение с базой данных conn.close()При работе с другими базами данных, используются дополнительные параметры соединения, например для PostrgeSQL:
conn = psycopg2.connect( host=hostname, user=username, password=password, dbname=database)Чтение из базы
# Делаем SELECT запрос к базе данных, используя обычный SQL-синтаксис cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT 3") # Получаем результат сделанного запроса results = cursor.fetchall() results2 = cursor.fetchall() print(results) # [('A Cor Do Som',), ('Aaron Copland & London Symphony Orchestra',), ('Aaron Goldberg',)] print(results2) # []Обратите внимание: После получения результата из курсора, второй раз без повторения самого запроса его получить нельзя — вернется пустой результат!
Запись в базу
# Делаем INSERT запрос к базе данных, используя обычный SQL-синтаксис cursor.execute("insert into Artist values (Null, 'A Aagrh!') ") # Если мы не просто читаем, но и вносим изменения в базу данных - необходимо сохранить транзакцию conn.commit() # Проверяем результат cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT 3") results = cursor.fetchall() print(results) # [('A Aagrh!',), ('A Cor Do Som',), ('Aaron Copland & London Symphony Orchestra',)]Примечание: Если к базе установлено несколько соединений и одно из них осуществляет модификацю базы, то база SQLite залочивается до завершения (метод соединения .commit()) или отмены (метод соединения .rollback()) транзакции.
Разбиваем запрос на несколько строк в тройных кавычках
Длинные запросы можно разбивать на несколько строк в произвольном порядке, если они заключены в тройные кавычки — одинарные (»’…»’) или двойные («»». «»»)
cursor.execute(""" SELECT name FROM Artist ORDER BY Name LIMIT 3 """)Конечно в таком простом примере разбивка не имеет смысла, но на сложных длинных запросах она может кардинально повышать читаемость кода.
Объединяем запросы к базе данных в один вызов метода
Метод курсора .execute() позволяет делать только один запрос за раз, при попытке сделать несколько через точку с запятой будет ошибка.
cursor.execute(""" insert into Artist values (Null, 'A Aagrh!'); insert into Artist values (Null, 'A Aagrh-2!'); """) # sqlite3.Warning: You can only execute one statement at a time. Для решения такой задачи можно либо несколько раз вызывать метод курсора .execute()
cursor.execute("""insert into Artist values (Null, 'A Aagrh!');""") cursor.execute("""insert into Artist values (Null, 'A Aagrh-2!');""")Либо использовать метод курсора .executescript()
cursor.executescript(""" insert into Artist values (Null, 'A Aagrh!'); insert into Artist values (Null, 'A Aagrh-2!'); """)Данный метод также удобен, когда у нас запросы сохранены в отдельной переменной или даже в файле и нам его надо применить такой запрос к базе.
Делаем подстановку значения в запрос
Важно! Никогда, ни при каких условиях, не используйте конкатенацию строк (+) или интерполяцию параметра в строке (%) для передачи переменных в SQL запрос. Такое формирование запроса, при возможности попадания в него пользовательских данных – это ворота для SQL-инъекций!
Правильный способ – использование второго аргумента метода .execute()
# C подставновкой по порядку на места знаков вопросов: cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT ?", ('2')) # И с использованием именнованных замен: cursor.execute("SELECT Name from Artist ORDER BY Name LIMIT :limit", )Примечание 1: В PostgreSQL (UPD: и в MySQL) вместо знака ‘?’ для подстановки используется: %s
Примечание 2: Таким способом не получится заменять имена таблиц, одно из возможных решений в таком случае рассматривается тут: stackoverflow.com/questions/3247183/variable-table-name-in-sqlite/3247553#3247553
UPD: Примечание 3: Благодарю Igelko за упоминание параметра paramstyle — он определяет какой именно стиль используется для подстановки переменных в данном модуле.
Вот ссылка с полезным приемом для работы с разными стилями подстановок.
Делаем множественную вставку строк проходя по коллекции с помощью метода курсора .executemany()
# Обратите внимание, даже передавая одно значение - его нужно передавать кортежем! # Именно по этому тут используется запятая в скобках! new_artists = [ ('A Aagrh!',), ('A Aagrh!-2',), ('A Aagrh!-3',), ] cursor.executemany("insert into Artist values (Null, ?);", new_artists)Получаем результаты по одному, используя метод курсора .fetchone()
Он всегда возвращает кортеж или None. если запрос пустой.
cursor.execute("SELECT Name FROM Artist ORDER BY Name LIMIT 3") print(cursor.fetchone()) # ('A Cor Do Som',) print(cursor.fetchone()) # ('Aaron Copland & London Symphony Orchestra',) print(cursor.fetchone()) # ('Aaron Goldberg',) print(cursor.fetchone()) # NoneВажно! Стандартный курсор забирает все данные с сервера сразу, не зависимо от того, используем мы .fetchall() или .fetchone()
Курсор как итератор
# Использование курсора как итератора for row in cursor.execute('SELECT Name from Artist ORDER BY Name LIMIT 3'): print(row) # ('A Cor Do Som',) # ('Aaron Copland & London Symphony Orchestra',) # ('Aaron Goldberg',)UPD: Повышаем устойчивость кода
Благодарю paratagas за ценное дополнение:
Для большей устойчивости программы (особенно при операциях записи) можно оборачивать инструкции обращения к БД в блоки «try-except-else» и использовать встроенный в sqlite3 «родной» объект ошибок, например, так:
try: cursor.execute(sql_statement) result = cursor.fetchall() except sqlite3.DatabaseError as err: print("Error: ", err) else: conn.commit()UPD: Использование with в psycopg2
with psycopg2.connect("dbname='habr'") as conn: with conn.cursor() as cur: Некоторые объекты в Python имеют __enter__ и __exit__ методы, что позволяет «чисто» взаимодействовать с ними, как в примере выше.
UPD: Ипользование row_factory
Благодарю remzalp за ценное дополнение:
Использование row_factory позволяет брать метаданные из запроса и обращаться в итоге к результату, например по имени столбца.
По сути — callback для обработки данных при возврате строки. Да еще и полезнейший cursor.description, где есть всё необходимое.
import sqlite3 def dict_factory(cursor, row): d = <> for idx, col in enumerate(cursor.description): d[col[0]] = row[idx] return d con = sqlite3.connect(":memory:") con.row_factory = dict_factory cur = con.cursor() cur.execute("select 1 as a") print(cur.fetchone()["a"])Дополнительные материалы (на английском)
- Краткий бесплатный он-лайн курс — Udacity — Intro to Relational Databases — Рассматриваются синтаксис и принципы работы SQL, Python DB-API – и теория и практика в одном флаконе. Очень рекомендую для начинающих!
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
How to Execute SQL Queries in Python and R Tutorial
Learn easy and effective ways to run SQL queries in Python and R for data analysis and database management.
What is SQL
Structured Query Language (SQL) is the most common language used for running various data analysis tasks. It is also used for maintaining a relational database, for example: adding tables, removing values, and optimizing the database. A simple relational database consists of multiple tables that are interconnected, and each table consists of rows and columns.
On average, a technology company generates millions of data points every day. A storage solution that is robust and effective is required so they can use the data to improve the current system or come up with a new product. A relational database such as MySQL, PostgreSQL, and SQLite solve these problems by providing robust database management, security, and high performance.
Core functionalities of SQL
- Create new tables in a database
- Execute queries against a database
- Retrieve data from a database
- Insert records into a database
- Update records in a database
- Delete records from a database
- Optimize any database
SQL is a high-demand skill that will help you land any job in the tech industry. Companies like Meta, Google, and Netflix are always on the lookout for data professionals that can extract information from SQL databases and come up with innovative solutions. You can learn the basics of SQL by taking the Introduction to SQL tutorial on DataCamp.
Why use SQL with Python and R?
SQL can help us discover the company’s performance, understand customer behaviors, and monitor the success metrics of marketing campaigns. Most data analysts can perform the majority of business intelligence tasks by running SQL queries, so why do we need tools such as PoweBI, Python, and R? By using SQL queries, you can tell what has happened in the past, but you cannot predict future projections. These tools help us understand more about the current performance and potential growth.
Python and R are multipurpose languages that allow professionals to run advanced statistical analysis, build machine learning models, create data APIs, and eventually help companies to think beyond KPIs. In this tutorial, we will learn to connect SQL databases, populate databases, and run SQL queries using Python and R.
Note: If you are new to SQL, then take the SQL skill track to understand the fundamentals of writing SQL queries.
Python Tutorial
The Python tutorial will cover the basics of connecting with various databases (MySQL and SQLite), creating tables, adding records, running queries, and learning about the Pandas function read_sql .
Setting Up
We can connect the database using SQLAlchemy, but in this tutorial, we are going to use the inbuilt Python package SQLite3 to run queries on the database. SQLAlchemy provides support for all kinds of databases by providing a unified API. If you are interested in learning more about SQLAlchemy and how it works with other databases then check out the Introduction to Databases in Python course.
MySQL is the most popular database engine in the world, and it is widely used by companies like Youtube, Paypal, LinkedIn, and GitHub. Here we will learn how to connect the database. The rest of the steps for using MySQL are similar to the SQLite3 package.
First, install the mysql package using ‘!pip install mysql’ and then create a local database engine by providing your username, password, and database name.
import mysql.connector as sql conn = sql.connect( host="localhost", user="abid", password="12345", database="datacamp_python" ) Similarly, we can create or load a SQLite database by using the sqlite3.connect function. SQLite is a library that implements a self-contained, zero-configuration, and serverless database engine. It is DataCamp Workspace friendly, so we will use it in our project to avoid local host errors.
import sqlite3 import pandas as pd conn= sqlite3.connect("datacamp_python.db")