- Saved searches
- Use saved searches to filter your results more quickly
- License
- catboost/tutorials
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- Быстрый градиентный бустинг с CatBoost
- Работа с категориальными признаками
- Преимущества использования CatBoost
- Параметры обучения
- Пример с регрессией
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
CatBoost tutorials repository
License
catboost/tutorials
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
It’s better to start CatBoost exploring from this basic tutorials.
- Python Tutorial
- This tutorial shows some base cases of using CatBoost, such as model training, cross-validation and predicting, as well as some useful features like early stopping, snapshot support, feature importances and parameters tuning.
- There are 17 questions in this tutorial. Try answering all of them, this will help you to learn how to use the library.
- R Tutorial
- This tutorial shows how to convert your data to CatBoost Pool, how to train a model and how to make cross validation and parameter tunning.
- Classification Tutorial
- Here is an example for CatBoost to solve binary classification and multi-classification problems.
- Feature selection Tutorial
- This tutorial shows how to make feature evaluation with CatBoost and explore learning rate.
- Object Importance Tutorial
- This tutorial shows how to evaluate importances of the train objects for test objects, and how to detect broken train objects by using the importance scores.
- This tutorial shows how to use SHAP python-package to get and visualize feature importances.
- This tutorial shows how to save catboost model in JSON format and apply it.
- This tutorial shows how to visualize catboost decision trees.
- This tutorial shows how to calculate feature statistics for catboost model.
- This tutorials shows how to use PredictionDiff feature importances.
- CatBoost CoreML Tutorial
- Explore this tutorial to learn how to convert CatBoost model to CoreML format and use it on any iOS device.
- Catboost model could be saved as standalone C++ code.
- Catboost model could be saved as standalone Python code.
- Explore how to apply CatBoost model from Java application. If you just want to look at code snippets you can go directly to CatBoost4jPredictionTutorial.java
- Explore how to apply CatBoost model from Rust application. If you just want to look at code snippets you can go directly to main.rs
- Convert LightGBM to CatBoost, save resulting CatBoost model and use CatBoost C++, Python, C# or other applier, which in case of not symmetric trees will be around 7-10 faster than native LightGBM one.
- Note that CatBoost applier with CatBoost models is even faster, because it uses specific fast symmetric trees.
- Gradient Boosting: CPU vs GPU
- This is a basic tutorial which shows how to run gradient boosting on CPU and GPU on Google Colaboratory.
- This is a basic tutorial which shows how to run regression on gradient boosting on CPU and GPU on Google Colaboratory.
- Kaggle Paribas Competition Tutorial
- This tutorial shows how to get to a 9th place on Kaggle Paribas competition with only few lines of code and training a CatBoost model.
- This is an actual 7th place solution by Mikhail Pershin. Solution is very simple and is based on CatBoost.
- This tutorial shows how to use CatBoost together with TensorFlow on Kaggle Quora Question Pairs competition if you have text as input data.
- PyData Moscow tutorial
- Tutorial from PyData Moscow, October 13, 2018.
- Tutorial from PyData New York, October 19, 2018.
- Tutorial from PyData Los Angeles, October 21, 2018.
- Tutorial from PyData Moscow, April 27, 2019.
- Tutorial from PyData London, June 15, 2019.
- Tutorial from PyData Boston, April 30, 2019.
Быстрый градиентный бустинг с CatBoost

В градиентном бустинге прогнозы делаются на основе ансамбля слабых обучающих алгоритмов. В отличие от случайного леса, который создает дерево решений для каждой выборки, в градиентном бустинге деревья создаются последовательно. Предыдущие деревья в модели не изменяются. Результаты предыдущего дерева используются для улучшения последующего. В этой статье мы подробнее познакомимся с библиотекой градиентного бустинга под названием CatBoost.
Источник
CatBoost — это библиотека градиентного бустинга, созданная Яндексом. Она использует небрежные (oblivious) деревья решений, чтобы вырастить сбалансированное дерево. Одни и те же функции используются для создания левых и правых разделений (split) на каждом уровне дерева.
Источник
По сравнению с классическими деревьями, небрежные деревья более эффективны при реализации на процессоре и просты в обучении.
Работа с категориальными признаками
Наиболее распространенными способами обработки категориальных данных в машинном обучении является one-hot кодирование и кодирование лейблов. CatBoost позволяет использовать категориальные признаки без необходимости их предварительно обрабатывать.
При использовании CatBoost мы не должны пользоваться one-hot кодированием, поскольку это влияет на скорость обучения и на качество прогнозов. Вместо этого мы просто задаем категориальные признаки с помощью параметра cat_features.
Преимущества использования CatBoost
Есть несколько причин подумать об использовании CatBoost:
- CatBoost позволяет проводить обучение на нескольких GPU.
- Библиотека позволяет получить отличные результаты с параметрами по умолчанию, что сокращает время, необходимое для настройки гиперпараметров.
- Обеспечивает повышенную точность за счет уменьшения переобучения.
- Возможность быстрого предсказания с применением модели CatBoost;
- Обученные модели CatBoost можно экспортировать в Core ML для вывода на устройстве (iOS).
- Умеет под капотом обрабатывать пропущенные значения.
- Может использоваться для регрессионных и классификационных задач.
Параметры обучения
Давайте рассмотрим общие параметры в CatBoost:
- loss_function или objective – показатель, используемый для обучения. Есть регрессионные показатели, такие как среднеквадратичная ошибка для регрессии и logloss для классификации.
- eval_metric – метрика, используемая для обнаружения переобучения.
- Iterations – максимальное количество построенных деревьев, по умолчанию 1000. Альтернативные названия num_boost_round , n_estimators и num_trees .
- learning_rate или eta – скорость обучения, которая определяет насколько быстро или медленно модель будет учиться. Значение по умолчанию обычно равно 0.03.
- random_seed или random_state – случайное зерно, используемое для обучения.
- l2_leaf_reg или reg_lambda – коэффициент при члене регуляризации L2 функции потерь. Значение по умолчанию – 3.0.
- bootstrap_type – определяет метод сэмплинга весов объектов, например это может быть Байес, Бернулли, многомерная случайная величина или Пуассон.
- depth = глубина дерева.
- grow_policy – определяет, как будет применяться жадный алгоритм поиска. Может стоять в значении SymmetricTree , Depthwise или Lossguide . По умолчанию SymmetricTree . В SymmetricTree дерево строится уровень за уровнем, пока не достигнет необходимой глубины. На каждом шаге листья с предыдущего дерева разделяются с тем же условием. При выборе параметра Depthwise дерево строится шаг за шагом, пока не достигнет необходимой глубины. Листья разделяются с использованием условия, которое приводит к лучшему уменьшению потерь. В Lossguide дерево строится по листьям до тех пор, пока не будет достигнуто заданное количество листьев. На каждом шаге разделяется нетерминальный лист с лучшим уменьшением потерь.
- min_data_in_leaf или min_child_samples – это минимальное количество обучающих сэмплов в листе. Этот параметр используется только с политиками роста Lossguide и Depthwise .
- max_leaves или num_leaves – этот параметр используется только с политикой Lossguide и определяет количество листьев в дереве.
- ignored_features — указывает на признаки, которые нужно игнорировать в процессе обучения.
- nan_mode – метод работы с пропущенными значениями. Параметры Forbidden, Min и Max . При использовании Forbidden наличие пропущенных значений вызовет ошибку. При использовании параметра Min пропущенные значения будут приняты за максимальные значения для данного признака. В Max пропущенные значения будут приняты как минимальные значения для данного признака.
- leaf_estimation_backtracking – тип бэктрекинга, использующийся при градиентном спуске. По умолчанию используется AnyImprovement . AnyImprovement уменьшает шаг спуска до того, как значение функции потерь будет меньшим, чем оно было на последней итерации. Armijo уменьшает шаг спуска до тех пор, пока не будет выполнено условие Вольфе.
- boosting_type — схема бустинга. Она может быть простой для классической схемы градиентного бустинга или упорядоченной, что обеспечит лучшее качество на небольших наборах данных.
- score_function – тип оценки, используемой для выбора следующего разбиения при построении дерева. Cosine используется по умолчанию. Другие доступные варианты L2, NewtonL2 и NewtonCosine .
- early_stopping_rounds — если стоит True , устанавливает тип детектора переобучения в Iter и останавливает обучение, когда достигается оптимальное значение.
- classes_count – количество классов для задач мультиклассификации.
- task_type – используете вы CPU или GPU. По умолчанию стоит CPU.
- devices — идентификаторы устройств GPU, которые будут использоваться для обучения.
- cat_features — массив с категориальными столбцами.
- text_features —используется для объявления текстовых столбцов в задачах классификации.
Пример с регрессией
CatBoost в своей реализации использует стандарт scikit-learn. Давайте посмотрим, как мы можем использовать его для регрессии.
Первый шаг, как всегда, импортировать регрессор и создать его экземпляр.
from catboost import CatBoostRegressor cat = CatBoostRegressor()При обучении модели CatBoost также позволяет нам визуализировать его, установив plot=true:
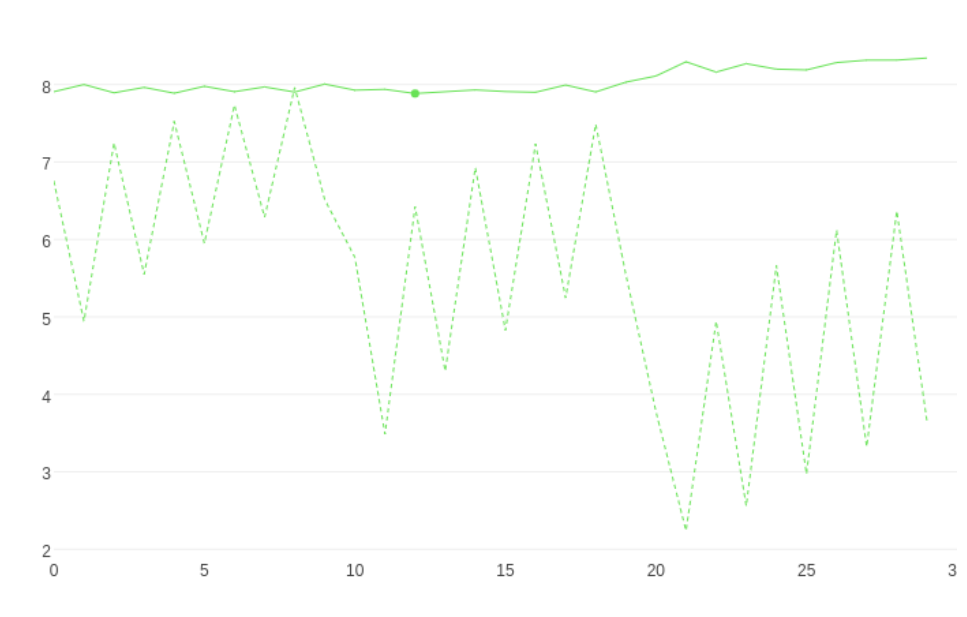
cat.fit(X_train,y_train,verbose=False, plot=True)Также мы можем выполнять кроссвалидацию и визуализировать процесс:
from catboost import Pool, cv params = cv_dataset = Pool(data=X_train, label=y_train) scores = cv(cv_dataset, params, fold_count=2, plot="True")Аналогично вы можете выполнить grid search и визуализировать его:
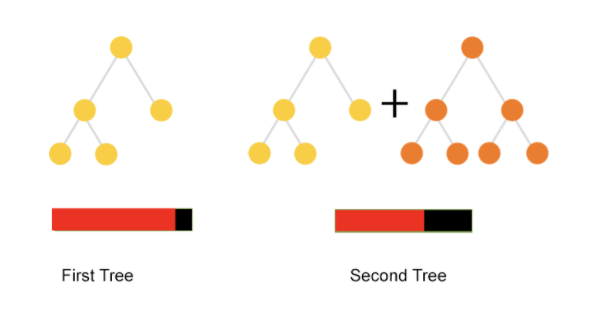
grid = grid_search_result = cat.grid_search(grid, X=X_train, y=y_train, plot=True)Также мы можем использовать CatBoost для построения дерева. Вот график первого дерева. Как вы видите из дерева, листья разделяются при одном и том же условии, например, 297, значение > 0.5.
CatBoost дает нам словарь со всеми параметрами модели. Мы можем вывести их, как словарь.
for key,value in cat.get_all_params().items(): print(‘<>, <>’.format(key,value))В этой статье мы рассмотрели преимущества и ограничения CatBoost, а также ее основные параметры обучения. Затем мы реализовали простую регрессию с помощью scikit-learn. Надеюсь, вы получили достаточно информации об этой библиотеке, чтобы самостоятельно продолжить ее исследование.