- ArrayList vs LinkedList in Java
- Java
- Java
- Java ArrayList vs LinkedList
- Get started with Spring 5 and Spring Boot 2, through the Learn Spring course:
- 1. Overview
- 2. ArrayList
- 2.1. Add
- 2.2. Access by Index
- 2.3. Remove by Index
- 2.4. Applications and Limitations
- 3. LinkedList
- 3.1. Add
- 3.2. Access by Index
- 3.3. Remove by Index
- 3.4. Applications
- 4. Conclusion
ArrayList vs LinkedList in Java
An array is a collection of items stored at contiguous memory locations. The idea is to store multiple items of the same type together. However, the limitation of the array is that the size of the array is predefined and fixed. There are multiple ways to solve this problem. In this article, the difference between two classes that are implemented to solve this problem named ArrayList and LinkedList is discussed.
ArrayList is a part of the collection framework. It is present in the java.util package and provides us dynamic arrays in Java. Though, it may be slower than standard arrays but can be helpful in programs where lots of manipulation in the array is needed. We can dynamically add and remove items. It automatically resizes itself. The following is an example to demonstrate the implementation of the ArrayList.
Java
LinkedList is a linear data structure where the elements are not stored in contiguous locations and every element is a separate object with a data part and address part. The elements are linked using pointers and addresses. Each element is known as a node. Due to the dynamicity and ease of insertions and deletions, they are preferred over the arrays. The following is an example to demonstrate the implementation of the LinkedList.
Java
[A, B, C] Linked list after deletion: [C]
Now after having an adequate understanding of both of them let us do discuss the differences between ArrayList and LinkedList in Java
| ArrayList | LinkedList | |
|---|---|---|
| 1. | This class uses a dynamic array to store the elements in it. With the introduction of generics, this class supports the storage of all types of objects. | This class uses a doubly linked list to store the elements in it. Similar to the ArrayList, this class also supports the storage of all types of objects. |
| 2. | Manipulating ArrayList takes more time due to the internal implementation. Whenever we remove an element, internally, the array is traversed and the memory bits are shifted. | Manipulating LinkedList takes less time compared to ArrayList because, in a doubly-linked list, there is no concept of shifting the memory bits. The list is traversed and the reference link is changed. |
| 3. | Inefficient memory utilization. | Good memory utilization. |
| 4. | It can be one, two or multi-dimensional. | It can either be single, double or circular LinkedList. |
| 5. | Insertion operation is slow. | Insertion operation is fast. |
| 6. | This class implements a List interface. Therefore, this acts as a list. | This class implements both the List interface and the Deque interface. Therefore, it can act as a list and a deque. |
| 7. | This class works better when the application demands storing the data and accessing it. | This class works better when the application demands manipulation of the stored data. |
| 8. | Data access and storage is very efficient as it stores the elements according to the indexes. | Data access and storage is slow in LinkedList. |
| 9. | Deletion operation is not very efficient. | Deletion operation is very efficient. |
| 10. | It is used to store only similar types of data. | It is used to store any types of data. |
| 11. | Less memory is used. | More memory is used. |
| 12. | The memory is allocated at compile-time only. | The memory is allocated at run-time. |
| 13. | This is known as static memory allocation. | This is known as dynamic memory allocation. |
ArrayList is an implementation of the List interface that uses an array to store its elements. It has a fast indexed access time, which means that retrieving elements from an ArrayList by an index is very quick.
For example, the following code demonstrates how to retrieve an element from an ArrayList:
Java ArrayList vs LinkedList
![]()
As always, the writeup is super practical and based on a simple application that can work with documents with a mix of encrypted and unencrypted fields.
![]()
We rely on other people’s code in our own work. Every day.
It might be the language you’re writing in, the framework you’re building on, or some esoteric piece of software that does one thing so well you never found the need to implement it yourself.
The problem is, of course, when things fall apart in production — debugging the implementation of a 3rd party library you have no intimate knowledge of is, to say the least, tricky.
Lightrun is a new kind of debugger.
It’s one geared specifically towards real-life production environments. Using Lightrun, you can drill down into running applications, including 3rd party dependencies, with real-time logs, snapshots, and metrics.
Learn more in this quick, 5-minute Lightrun tutorial:
![]()
Slow MySQL query performance is all too common. Of course it is. A good way to go is, naturally, a dedicated profiler that actually understands the ins and outs of MySQL.
The Jet Profiler was built for MySQL only, so it can do things like real-time query performance, focus on most used tables or most frequent queries, quickly identify performance issues and basically help you optimize your queries.
Critically, it has very minimal impact on your server’s performance, with most of the profiling work done separately — so it needs no server changes, agents or separate services.
Basically, you install the desktop application, connect to your MySQL server, hit the record button, and you’ll have results within minutes:
![]()
DbSchema is a super-flexible database designer, which can take you from designing the DB with your team all the way to safely deploying the schema.
The way it does all of that is by using a design model, a database-independent image of the schema, which can be shared in a team using GIT and compared or deployed on to any database.
And, of course, it can be heavily visual, allowing you to interact with the database using diagrams, visually compose queries, explore the data, generate random data, import data or build HTML5 database reports.
Get started with Spring 5 and Spring Boot 2, through the Learn Spring course:
1. Overview
When it comes to collections, the Java standard library provides plenty of options to choose from. Among those options are two famous List implementations known as ArrayList and LinkedList, each with their own properties and use-cases.
In this tutorial, we’re going to see how these two are actually implemented. Then, we’ll evaluate different applications for each one.
2. ArrayList
Internally, ArrayList is using an array to implement the List interface. As arrays are fixed size in Java, ArrayList creates an array with some initial capacity. Along the way, if we need to store more items than that default capacity, it will replace that array with a new and more spacious one.
To better understand its properties, let’s evaluate this data structure with respect to its three main operations: adding items, getting one by index and removing by index.
2.1. Add
When we’re creating an empty ArrayList, it initializes its backing array with a default capacity (currently 10):

Adding a new item while that array it not yet full is as simple as assigning that item to a specific array index. This array index is determined by the current array size since we’re practically appending to the list:
backingArray[size] = newItem; size++;So, in best and average cases, the time complexity for the add operation is O(1), which is pretty fast. As the backing array becomes full, however, the add implementation becomes less efficient:
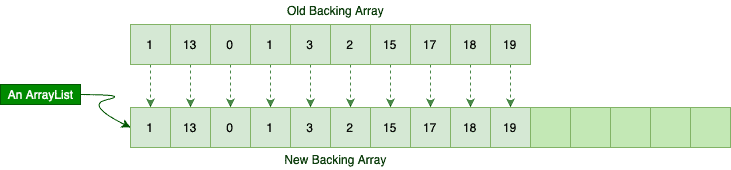
To add a new item, we should first initialize a brand new array with more capacity and copy all existing items to the new array. Only after copying current elements can we add the new item. Hence, the time complexity is O(n) in the worst case since we have to copy n elements first.
Theoretically speaking, adding a new element runs in amortized constant time. That is, adding n elements requires O(n) time. However, some single additions may perform poorly because of the copy overhead.
2.2. Access by Index
Accessing items by their indices is where the ArrayList really shines. To retrieve an item at index i, we just have to return the item residing at the i th index from the backing array. Consequently, the time complexity for access by index operation is always O(1).
2.3. Remove by Index
Suppose we’re going to remove the index 6 from our ArrayList, which corresponds to the element 15 in our backing array:
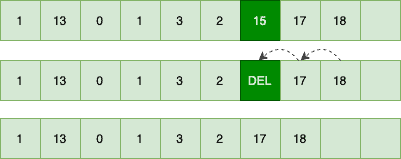
After marking the desired element as deleted, we should move all elements after it back by one index. Obviously, the nearer the element to the start of the array, the more elements we should move. So the time complexity is O(1) at the best-case and O(n) on average and worst-cases.
2.4. Applications and Limitations
Usually, ArrayList is the default choice for many developers when they need a List implementation. As a matter of fact, it’s actually a sensible choice when the number of reads is far more than the number of writes.
Sometimes we need equally frequent reads and writes. If we do have an estimate of the maximum number of possible items, then it still makes sense to use ArrayList. If that’s the case, we can initialize the ArrayList with an initial capacity:
int possibleUpperBound = 10_000; List items = new ArrayList<>(possibleUpperBound);This estimation may prevent lots of unnecessary copying and array allocations.
Moreover, arrays are indexed by int values in Java. So, it’s not possible to store more than 2 32 elements in a Java array and, consequently, in ArrayList.
3. LinkedList
LinkedList, as its name suggests, uses a collection of linked nodes to store and retrieve elements. For instance, here’s how the Java implementation looks after adding four elements:

Each node maintains two pointers: one pointing to the next element and another referring to the previous one. Expanding on this, the doubly linked list has two pointers pointing to the first and last items.
Again, let’s evaluate this implementation with respect to the same fundamental operations.
3.1. Add
In order to add a new node, first, we should link the current last node to the new node:

And then update the last pointer:

As both of these operations are trivial, the time complexity for the add operation is always O(1).
3.2. Access by Index
LinkedList, as opposed to ArrayList, does not support fast random access. So, in order to find an element by index, we should traverse some portion of the list manually.
In the best case, when the requested item is near the start or end of the list, the time complexity would be as fast as O(1). However, in the average and worst-case scenarios, we may end up with an O(n) access time since we have to examine many nodes one after another.
3.3. Remove by Index
In order to remove an item, we should first find the requested item and then un-link it from the list. Consequently, the access time determines the time complexity — that is, O(1) at best-case and O(n) on average and in worst-case scenarios.
3.4. Applications
LinkedLists are more suitable when the addition rate is much higher than the read rate.
Also, it can be used in read-heavy scenarios when most of the time we want the first or last element. It’s worth mentioning that LinkedList also implements the Deque interface – supporting efficient access to both ends of the collection.
Generally, if we know their implementation differences, then we could easily choose one for a particular use-case.
For instance, let’s say that we’re going store a lot of time-series events in a list-like data structure. We know that we would receive bursts of events each second.
Also, we need to examine all events one after another periodically and provide some stats. For this use-case, LinkedList is a better choice because the addition rate is much higher than the read rate.
Also, we would read all the items, so we can’t beat the O(n) upper bound.
4. Conclusion
In this tutorial, first, we took a dive into how ArrayList and LinkLists are implemented in Java.
We also evaluated different use-cases for each one of these.
![]()
Slow MySQL query performance is all too common. Of course it is. A good way to go is, naturally, a dedicated profiler that actually understands the ins and outs of MySQL.
The Jet Profiler was built for MySQL only, so it can do things like real-time query performance, focus on most used tables or most frequent queries, quickly identify performance issues and basically help you optimize your queries.
Critically, it has very minimal impact on your server’s performance, with most of the profiling work done separately — so it needs no server changes, agents or separate services.
Basically, you install the desktop application, connect to your MySQL server, hit the record button, and you’ll have results within minutes: