- Table API Tutorial #
- What Will You Be Building? #
- Prerequisites #
- Help, I’m Stuck! #
- How To Follow Along #
- Writing a Flink Python Table API Program #
- Executing a Flink Python Table API Program #
- Saved searches
- Use saved searches to filter your results more quickly
- wdm0006/flink-python-examples
- Name already in use
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
Table API Tutorial #
Apache Flink offers a Table API as a unified, relational API for batch and stream processing, i.e., queries are executed with the same semantics on unbounded, real-time streams or bounded, batch data sets and produce the same results. The Table API in Flink is commonly used to ease the definition of data analytics, data pipelining, and ETL applications.
What Will You Be Building? #
In this tutorial, you will learn how to build a pure Python Flink Table API pipeline. The pipeline will read data from an input csv file, compute the word frequency and write the results to an output file.
Prerequisites #
This walkthrough assumes that you have some familiarity with Python, but you should be able to follow along even if you come from a different programming language. It also assumes that you are familiar with basic relational concepts such as SELECT and GROUP BY clauses.
Help, I’m Stuck! #
If you get stuck, check out the community support resources. In particular, Apache Flink’s user mailing list consistently ranks as one of the most active of any Apache project and a great way to get help quickly.
How To Follow Along #
If you want to follow along, you will require a computer with:
Using Python Table API requires installing PyFlink, which is available on PyPI and can be easily installed using pip .
$ python -m pip install apache-flink Once PyFlink is installed, you can move on to write a Python Table API job.
Writing a Flink Python Table API Program #
Table API applications begin by declaring a table environment. This serves as the main entry point for interacting with the Flink runtime. It can be used for setting execution parameters such as restart strategy, default parallelism, etc. The table config allows setting Table API specific configurations.
t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) t_env.get_config().set("parallelism.default", "1") You can now create the source and sink tables:
t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) You can also use the TableEnvironment.execute_sql() method to register a source/sink table defined in DDL:
my_source_ddl = """ create table source ( word STRING ) with ( 'connector' = 'filesystem', 'format' = 'csv', 'path' = '<>' ) """.format(input_path) my_sink_ddl = """ create table sink ( word STRING, `count` BIGINT ) with ( 'connector' = 'filesystem', 'format' = 'canal-json', 'path' = '<>' ) """.format(output_path) t_env.execute_sql(my_source_ddl) t_env.execute_sql(my_sink_ddl) This registers a table named source and a table named sink in the table environment. The table source has only one column, word, and it consumes strings read from file specified by input_path . The table sink has two columns, word and count, and writes data to the file specified by output_path .
You can now create a job which reads input from table source , performs some transformations, and writes the results to table sink .
Finally, you must execute the actual Flink Python Table API job. All operations, such as creating sources, transformations and sinks are lazy. Only when execute_insert(sink_name) is called, the job will be submitted for execution.
@udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf word_count_data = ["To be, or not to be,--that is the question:--", "Whether 'tis nobler in the mind to suffer", "The slings and arrows of outrageous fortune", "Or to take arms against a sea of troubles,", "And by opposing end them?--To die,--to sleep,--", "No more; and by a sleep to say we end", "The heartache, and the thousand natural shocks", "That flesh is heir to,--'tis a consummation", "Devoutly to be wish'd. To die,--to sleep;--", "To sleep! perchance to dream:--ay, there's the rub;", "For in that sleep of death what dreams may come,", "When we have shuffled off this mortal coil,", "Must give us pause: there's the respect", "That makes calamity of so long life;", "For who would bear the whips and scorns of time,", "The oppressor's wrong, the proud man's contumely,", "The pangs of despis'd love, the law's delay,", "The insolence of office, and the spurns", "That patient merit of the unworthy takes,", "When he himself might his quietus make", "With a bare bodkin? who would these fardels bear,", "To grunt and sweat under a weary life,", "But that the dread of something after death,--", "The undiscover'd country, from whose bourn", "No traveller returns,--puzzles the will,", "And makes us rather bear those ills we have", "Than fly to others that we know not of?", "Thus conscience does make cowards of us all;", "And thus the native hue of resolution", "Is sicklied o'er with the pale cast of thought;", "And enterprises of great pith and moment,", "With this regard, their currents turn awry,", "And lose the name of action.--Soft you now!", "The fair Ophelia!--Nymph, in thy orisons", "Be all my sins remember'd."] def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() # remove .wait if submitting to a remote cluster, refer to # https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/python/faq/#wait-for-jobs-to-finish-when-executing-jobs-in-mini-cluster # for more details if __name__ == '__main__': logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") parser = argparse.ArgumentParser() parser.add_argument( '--input', dest='input', required=False, help='Input file to process.') parser.add_argument( '--output', dest='output', required=False, help='Output file to write results to.') argv = sys.argv[1:] known_args, _ = parser.parse_known_args(argv) word_count(known_args.input, known_args.output) Executing a Flink Python Table API Program #
You can run this example on the command line:
The command builds and runs the Python Table API program in a local mini cluster. You can also submit the Python Table API program to a remote cluster, you can refer Job Submission Examples for more details.
Finally, you can see the execution results similar to the following:
This should get you started with writing your own Flink Python Table API programs. You can also refer to PyFlink Examples for more examples. To learn more about the Python Table API, you can refer Flink Python API Docs for more details.
Saved searches
Use saved searches to filter your results more quickly
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session. You switched accounts on another tab or window. Reload to refresh your session.
A collection of examples using flinks new python API
wdm0006/flink-python-examples
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Name already in use
A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
A collection of examples using Apache Flink™’s new python API. To set up your local environment with the latest Flink build, see the guide:
The examples here use the v0.10.0 python API, and are meant to serve as demonstrations of simple use cases. Currently the python API supports a portion of the DataSet API, which has a similar functionality to Spark, from the user’s perspective.
To run the examples, I’ve included a runner script at the top level with methods for each example, simply add in the path to your pyflink script and you should be good to go (as long as you have a flink cluster running locally).
The currently included examples are:
A listing of the examples and their resultant flink plans are included here.
An extremely simple analysis program uses a source from a simple string, counts the occurrences of each word and outputs to a file on disk (using the overwrite functionality).

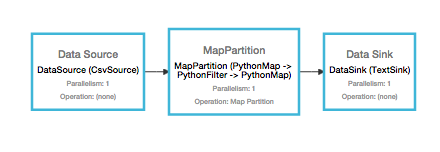
A very similar example to word count, but includes a filter step to only include hashtags, and different source/sinks. The input data in this case is read off of disk, and the output is written as a csv. The file is generated dynamically at run time, so you can play with different volumes of tweets to get an idea of Flink’s scalability and performance.
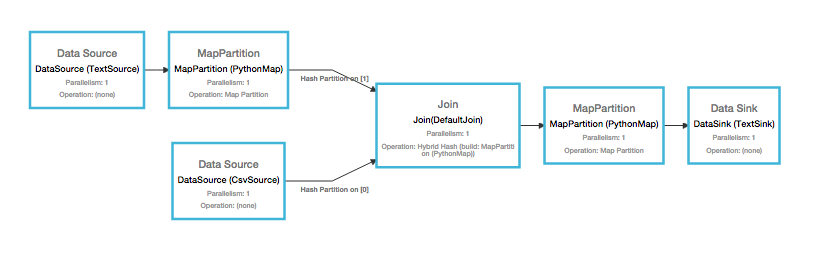
In this example, we have row-wise json in one file, with an attribute field that refers to a csv dimension table with colors. So we load both datasets in, convert the json data into a ordered and typed tuple, and join then two together to get a nice dataset of cars and their colors.
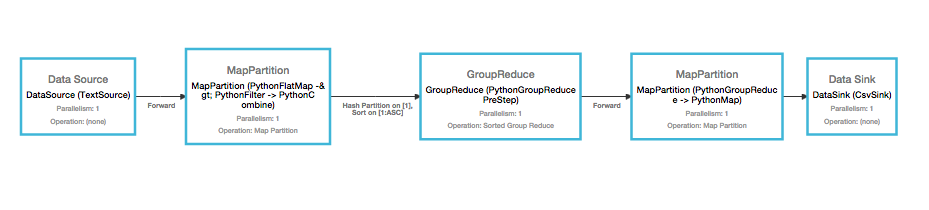
Takes in a csv with two columns and finds the mean of each column, using a custom reducer function. Afterwards, it formats a string nicely with the output and dumps that onto disk.

Creates a Mandelbrot set from a set of candidates. Inspired by this post
A quick listing of high level features, and the examples that include them
Text data-source (read_text)
String data-source (from_elements)
Log to stdout output (output)
- word count
- trending hashtags
- data enrichment
- mean values
- mandelbrot