- Html code in java class
- Modifying HTMLDocument
- Inserting elements
- Replacing elements
- Summary
- How to Use HTML in Swing Components
- An Example: HtmlDemo
- Example 2: ButtonHtmlDemo
- 3 примера как разобрать HTML-файл в Java используя Jsoup
- Что такое Jsoup
- Разбор HTML в Java используя Jsoup
- Java программа для разбора HTML документа
Html code in java class
A document that models HTML. The purpose of this model is to support both browsing and editing. As a result, the structure described by an HTML document is not exactly replicated by default. The element structure that is modeled by default, is built by the class HTMLDocument.HTMLReader , which implements the HTMLEditorKit.ParserCallback protocol that the parser expects. To change the structure one can subclass HTMLReader , and reimplement the method getReader(int) to return the new reader implementation. The documentation for HTMLReader should be consulted for the details of the default structure created. The intent is that the document be non-lossy (although reproducing the HTML format may result in a different format). The document models only HTML, and makes no attempt to store view attributes in it. The elements are identified by the StyleContext.NameAttribute attribute, which should always have a value of type HTML.Tag that identifies the kind of element. Some of the elements (such as comments) are synthesized. The HTMLFactory uses this attribute to determine what kind of view to build. This document supports incremental loading. The TokenThreshold property controls how much of the parse is buffered before trying to update the element structure of the document. This property is set by the EditorKit so that subclasses can disable it. The Base property determines the URL against which relative URLs are resolved. By default, this will be the Document.StreamDescriptionProperty if the value of the property is a URL. If a tag is encountered, the base will become the URL specified by that tag. Because the base URL is a property, it can of course be set directly. The default content storage mechanism for this document is a gap buffer ( GapContent ). Alternatives can be supplied by using the constructor that takes a Content implementation.
Modifying HTMLDocument
The following examples illustrate using these methods. Each example assumes the HTML document is initialized in the following way:
JEditorPane p = new JEditorPane(); p.setContentType("text/html"); p.setText(". "); // Document text is provided below. HTMLDocument d = (HTMLDocument) p.getDocument(); With the following HTML content:
div < background-color: silver; >ulParagraph 1
Paragraph 2
All the methods for modifying an HTML document require an Element . Elements can be obtained from an HTML document by using the method getElement(Element e, Object attribute, Object value) . It returns the first descendant element that contains the specified attribute with the given value, in depth-first order. For example, d.getElement(d.getDefaultRootElement(), StyleConstants.NameAttribute, HTML.Tag.P) returns the first paragraph element.
A convenient shortcut for locating elements is the method getElement(String) ; returns an element whose ID attribute matches the specified value. For example, d.getElement(«BOX») returns the DIV element.
The getIterator(HTML.Tag t) method can also be used for finding all occurrences of the specified HTML tag in the document.
Inserting elements
Replacing elements
Summary
The following table shows the example document and the results of various methods described above.
How to Use HTML in Swing Components
Many Swing components display a text string as part of their GUI. By default, a component’s text is displayed in a single font and color, all on one line. You can determine the font and color of a component’s text by invoking the component’s setFont and setForeground methods, respectively. For example, the following code creates a label and then sets its font and color:
label = new JLabel("A label"); label.setFont(new Font("Serif", Font.PLAIN, 14)); label.setForeground(new Color(0xffffdd)); If you want to mix fonts or colors within the text, or if you want formatting such as multiple lines, you can use HTML. HTML formatting can be used in all Swing buttons, menu items, labels, tool tips, and tabbed panes, as well as in components such as trees and tables that use labels to render text.
To specify that a component’s text has HTML formatting, just put the tag at the beginning of the text, then use any valid HTML in the remainder. Here is an example of using HTML in a button’s text:
button = new JButton("Two
lines"); Here is the resulting button.
An Example: HtmlDemo
An application called HtmlDemo lets you play with HTML formatting by setting the text on a label. You can find the entire code for this program in HtmlDemo.java . Here is a picture of the HtmlDemo example.

Try This:
- Click the Launch button to run HtmlDemo using Java™ Web Start (download JDK 7 or later). Alternatively, to compile and run the example yourself, consult the example index.
- Edit the HTML formatting in the text area at the left and click the «Change the label» button. The label at the right shows the result.
- Remove the tag from the text area on the left. The label’s text is no longer parsed as HTML.
Example 2: ButtonHtmlDemo
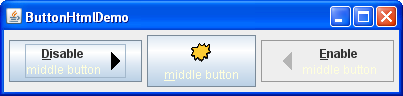
Let us look at another example that uses HTML. ButtonHtmlDemo adds font, color, and other text formatting to three buttons. You can find the entire code for this program in ButtonHtmlDemo.java . Here is a picture of the ButtonHtmlDemo example.
Click the Launch button to run ButtonHtmlDemo using Java™ Web Start (download JDK 7 or later). Alternatively, to compile and run the example yourself, consult the example index.
The left and right buttons have multiple lines and text styles and are implemented using HTML. The middle button, on the other hand, uses just one line, font, and color, so it does not require HTML. Here is the code that specifies the text formatting for these three buttons:
b1 = new JButton("Disable
" + "middle button", leftButtonIcon); Font font = b1.getFont().deriveFont(Font.PLAIN); b1.setFont(font); . b2 = new JButton("middle button", middleButtonIcon); b2.setFont(font); b2.setForeground(new Color(0xffffdd)); . b3 = new JButton("Enable
" + "middle button", rightButtonIcon); b3.setFont(font); Note that we have to use a tag to cause the mnemonic characters «D» and «E» to be underlined in the buttons that use HTML. Note also that when a button is disabled, its HTML text unfortunately remains black, instead of becoming gray. (Refer to bug #4783068 to see if this situation changes.)
This section discussed how to use HTML in ordinary, non-text components. For information on components whose primary purpose is formatting text, see Using Text Components.
If you are programming in JavaFX, see HTML Editor.
3 примера как разобрать HTML-файл в Java используя Jsoup


HTML это ядро WEB, все интернет-страницы которые Вы видите, являются ли они динамически сгенерированы средствами JavaScript, JSP, PHP, ASP или другими веб-технологиями, основаны на HTML. На самом деле, Ваш браузер разбирает HTML и отображает его в удобном для Вас виде. Но что делать если Вам нужно разобрать HTML-документ и найти в нем некоторый элемент, тэг, атрибут или проверить существует или нет конкретный элемент при помощи программы на Java. Если бы Вы были Java программистом уже несколько лет, я уверен, Вы бы сделали XML разбор используя парсеры вроде DOM или SAX. Но, по иронии судьбы, бывают случаи, когда Вам необходимо разобрать HTML-документ из базового Java приложения, которое не содержит Servlet и другие Java веб-технологии. Более того, Core JDK также не содержит HTTP или HTML библиотек. Вот почему, когда дело доходит до разбора HTML файла, многие Java программисты спрашивают у Google, как получить значение HTML-тэга в Java. Когда я столкнулся с этим, я был уверен что решением будет open-source библиотека, осуществляющая нужную мне функциональность, но я не знал, что она будет такой замечательной и многофункциональной как Jsoup. Она не только обеспечивает поддержку чтения и разбора HTML файлов, атрибутов, CSS классов в стиле JQuery, но и в то же время, позволяет модифицировать их. Используя Jsoup Вы можете сделать с HTML документом все что угодно. В этой статье мы будем разбирать HTML файл и находить названия и атрибуты тэгов. Также мы разберем примеры скачивания и разбора HTML из файла и любого URL-адреса, например домашнюю страницу Google.
Что такое Jsoup
- Jsoup может очистить и разобрать HTML из URL, файла или строки.
- Jsoup может найти и извлечь данные используя обход DOM или CSS селекторы.
- Jsoup позволяет манипулировать HTML элементами, атрибутами и текстом.
- Jsoup обеспечивает очистку предоставленной пользователем информации по white-list, для предотвращения XSS атак.
- Также Jsoup выдает «аккуратный» HTML.
Разбор HTML в Java используя Jsoup
В этом учебнике мы увидим три различных примера разбора и обхода HTML-документа в Java используя Jsoup. В первом примере, мы будем разбирать HTML строку, содержащую тэги, в форме строкового литерала Java. Во втором примере, мы скачаем наш HTML-документ из интернет, и в третьем примере, мы загрузим для разбора наш собственный образец HTML файла login.html. Этот файл — образец HTML документа, который состоит из тэга «title» и тэга «div» в секции «body», который содержит HTML форму. В форме находятся поля для ввода имени пользователя и пароля, а также кнопки сброса и подтверждения для дальнейших действий. Это «правильный» HTML, который может пройти проверку на «валидность», то есть все тэги и атрибуты правильно закрыты. Вот как выглядит наш HTML файл:
С помощью Jsoup очень просто разобрать HTML, все что Вам нужно это вызвать статический метод Jsoup.parse() и передать в него Вашу HTML строку. Jsoup предоставляет несколько перегруженных методов parse() для чтения HTML из строки, файла, из базового URI, из URL и из InputStream . Вы также можете указать кодировку, для корректного чтения HTML файла, в случае если он не в формате «UTF-8». Метод parse(String html) разбирает входящий HTML в новый объект Document . В Jsoup класс Document наследует класс Element , который расширяет класс Node . Также от класса Node наследуется класс TextNode . До тех пор, пока Вы передаете в метод строку отличную от null, Вы гарантированно имеете успешный, осмысленный разбор, объект Document содержащий (по крайней мере) элементы «head» и «body». Если у Вас есть объект Document , Вы можете получить желаемые данные вызвав соответствующие методы класса Document и его родителей Element и Node .
Java программа для разбора HTML документа
Вот наша полная программа для разбора HTML-строки, HTML-файла, скачанного из интернет и локального HTML файла. Для ее запуска Вы можете использовать IDE (Eclipse или любую другую) или командную строку. В Eclipse это очень легко, просто скопируйте этот код, создайте новый Java проект, щелкните правой кнопкой мыши по папке «src» и вставьте скопированный код (paste). Eclipse позаботится о создании надлежащего пакета и файла исходного кода с соответствующим именем, так гораздо меньше работы. Если у Вас уже есть Java проект, тогда это всего один шаг. Расположенная ниже программа иллюстрирует три примера разбора и обхода HTML файла. В первом примере, мы непосредственно разбираем строку, содержащую HTML, во втором HTML-файл скачанный из URL, в третьем мы загружаем и разбираем HTML-документ из локальной файловой системы.
import java.io.File; import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; /** * Java Program to parse/read HTML documents from File using Jsoup library. * Jsoup is an open source library which allows Java developer to parse HTML * files and extract elements, manipulate data, change style using DOM, CSS and * JQuery like method. * * @author Javin Paul */ public class HTMLParser< public static void main(String args[]) < // Parse HTML String using JSoup library String HTMLSTring = "" + "" + "" + "" + "" + "" + "HelloWorld
" + "" + ""; Document html = Jsoup.parse(HTMLSTring); String title = html.title(); String h1 = html.body().getElementsByTag("h1").text(); System.out.println("Input HTML String to JSoup :" + HTMLSTring); System.out.println("After parsing, Title : " + title); System.out.println("Afte parsing, Heading : " + h1); // JSoup Example 2 - Reading HTML page from URL Document doc; try < doc = Jsoup.connect("http://google.com/").get(); title = doc.title(); >catch (IOException e) < e.printStackTrace(); >System.out.println("Jsoup Can read HTML page from URL, title : " + title); // JSoup Example 3 - Parsing an HTML file in Java //Document htmlFile = Jsoup.parse("login.html", "ISO-8859-1"); // wrong Document htmlFile = null; try < htmlFile = Jsoup.parse(new File("login.html"), "ISO-8859-1"); >catch (IOException e) < // TODO Auto-generated catch block e.printStackTrace(); >// right title = htmlFile.title(); Element div = htmlFile.getElementById("login"); String cssClass = div.className(); // getting class form HTML element System.out.println("Jsoup can also parse HTML file directly"); System.out.println("title : " + title); System.out.println("class of div tag : " + cssClass); > > Input HTML String to JSoup :HelloWorld
After parsing, Title : JSoup Example Afte parsing, Heading : HelloWorld Jsoup Can read HTML page from URL, title : Google Jsoup can also parse HTML file directly title : Login Page class of div tag : simple