Экспресс-анализ данных на Python
В рамках расширения своих компетенций периодически провожу анализ данных датасетов. В какой-то момент осознал, что трачу время на столбцы с аналитиками, в которых все в порядке. Данные полные, тип данных единый, интерпретация понятна. Если столбцов несколько десятков, то обзорная проверка атрибутов каждого столбца занимает довольно значительное время.
Посмотрел в сторону библиотеки pandas-profiling.
Мне показалось, что инструмент хорошо подходит для датасета в котором отработаны аномалии, пропуски, выбросы, типы данных. Вызвав df.profile_report() получаешь добротный отчет и остается только рыться во всех вкладках отчета и анализировать интересующие столбцы.
Меня смутил большой объем информации, который выдает profile_report(). Мне не хватило более простой обзорной формы, где легко можно сделать вывод и решить для себя стоит обратить внимание на столбец или нет. Возникла потребность самому настроить выдачу отчета под себя.
Разработчиком я не являюсь, поэтому попытался накидать простой код своими силами, который бы позволил немного ускорить процесс проверки. Возможно он поможет и вам. Был бы признателен, если в комментариях, напишите ваше предложение, что можно улучшить, добавить, скорректировать.
Требования и план разработки
При построении нужно предусмотреть добавление функций для анализа данных, если возникнет потребность расширить пул анализируемых параметров. Возможность вызывать, как отдельную функцию с конкретным анализом, так и все сразу. Функции должны перебирать каждый столбец в DateFrame.
Подумав над решением пришел к выводу, что понадобиться класс, в котором инициализируются переменные, которые будут доступны всем функциям. Графически вижу это так:
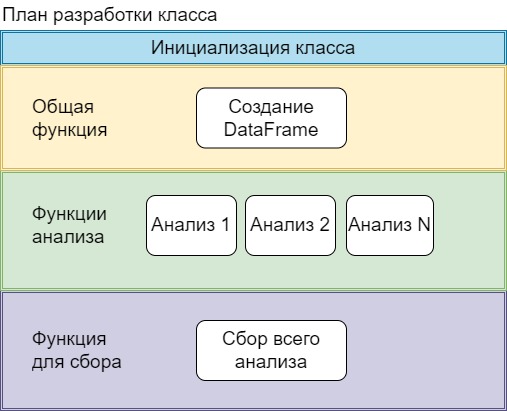
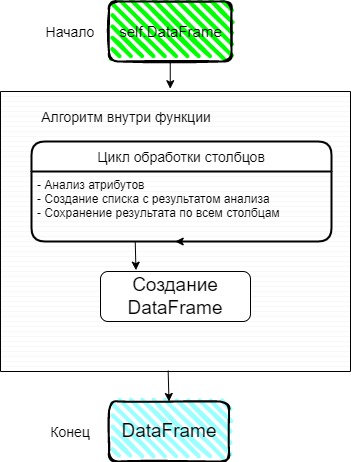
Подумал, как выстроить алгоритм для анализа столбцов. На вход функция получает таблицу с данными, анализирует через цикл каждый столбец. По итогу должна родиться строка с результатом. Один столбец = одной строке с результатом.
Функция должна иметь возможность быть вызвана независимо от других, следовательно, чтобы удовлетворить это требование результатом работы (return) должен быть DateFrame
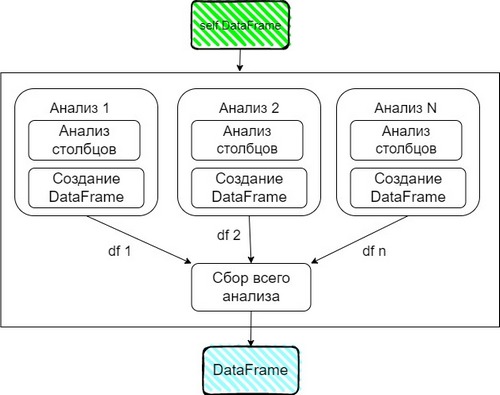
Функция вывода всех результатов анализа, решил построить следующим образом
Разработка
Инициализируем класс
import pandas as pd class DataAnalysisColumns(): def __init__(self, df: pd.DataFrame): self.df = df self.columns = df.columns self.TotalRows = df.shape[0] self.BoxResult = [] self.СolumnsDict =
Делаем доступными для функций:
Список с названием столбцов
Общие количество строк. Понадобиться для части функций.
Пустой список для сохранения результата анализа столбцов.
Словарь с названиями столбцов итогового отчета.
Общая функция
CreateDf принимает список с результатом анализа и создает DataFrame. Очищает список, в котором хранились результаты с целью использования в следующих функциях.
def CreateDf(self,BoxResult:list): OutputDf = pd.DataFrame(data=BoxResult, columns=list(self.СolumnsDict.keys())) self.BoxResult.clear() return OutputDf Функции анализа
Напишем несколько простых функций с анализом. Проанализируем имена столбцов на предмет наличия пробелов. Ранее при использовании query в pandas пробелы в названиях столбцов попортили нервы.
Второй анализ будет связан с наличием пустых строк в столбце. Выведем абсолютное и относительное число.
Каждая функция завершается созданием отдельного dataframe
def AnalysisOfColumnNames(self): for NameColumn in self.columns: if " " in NameColumn: ListAttributes = ['Сolumn name', NameColumn, NameColumn] self.BoxResult.append(ListAttributes) return self.CreateDf(self.BoxResult) def AnalysisOfNull(self): for NameColumn in self.columns: CountNull = self.df[NameColumn].isnull().sum() if CountNull > 0: ListAttributes = ['Null Count', NameColumn , f' of or ".format(CountNull/self.TotalRows)>'] self.BoxResult.append(ListAttributes) return self.CreateDf(self.BoxResult) Третья функция немного сложнее. Анализируем состав типа данных внутри столбца. Результаты выводим так же в абсолютных и относительных значениях.
В строках 18-20 пытаюсь выдернуть из , тип данных c кавычки ‘str’. Переменные FirsttNumOfSymbol, LatsNumOfSymbol. Наверное, его можно заменить регулярным выражением. Пытался сделать не получилось. Был бы рад, если в комментариях подскажите это сократит код.
def AnalysisOfType(self): # анализируем каждый столбец for NameColumn in self.columns: TypeColumn = str(self.df[NameColumn].dtype) # для типа 'object' пробегаемся по всему столбцу # формируем сводную по типу данных и считаем кол-ву строк if TypeColumn == 'object': self.df['TypeData'] = self.df[NameColumn].apply(lambda x: str(type(x))) PivotTable = self.df.groupby('TypeData').agg().reset_index() PivotTable.columns = ['TypeData', 'count'] ColumnType = PivotTable['TypeData'] BoxResult = [] # собираем все в один результат(строку) for i in range(len(PivotTable)): FirsttNumOfSymbol = ColumnType[i].find("'") LatsNumOfSymbol = ColumnType[i].rfind("'") + 1 NameTypeRow = ColumnType[i][FirsttNumOfSymbol:LatsNumOfSymbol] Percent = "".format(PivotTable['count'][i]/self.TotalRows) StringForAppend = f":()" BoxResult.append(StringForAppend) ListAttributes = ['Type', NameColumn, ",".join(BoxResult)] self.BoxResult.append(ListAttributes) return self.CreateDf(self.BoxResult) Функции для анализа выбросов и анализ уникальности я оставлю в коде на GitHub.
Сбор всего анализа
Наши функции выдают отдельные DataFrame, соберем их в отдельный список. При помощи concat объединим в один.
В качестве демонстрации работы с итоговой таблицей, изменил порядок столбцов и добавил сортировку.
def AnalysisOfDf(self): ListOfAnalysis = [self.AnalysisOfColumnNames(), self.AnalysisOfNull(), self.AnalysisOfType(), self.AnalysisOfOutlier(), self.AnalysisOfUniqueText(), ] OutputDf = pd.concat(ListOfAnalysis).reset_index(drop=True) OutputDf = OutputDf[['NameColumns', 'AnalysisParams', 'Value']] return OutputDf.sort_values(by=['NameColumns']).reset_index(drop=True)Результат
Тестируем на реальных данных. Вызовем весь анализ. Размер таблицы (7043, 24)
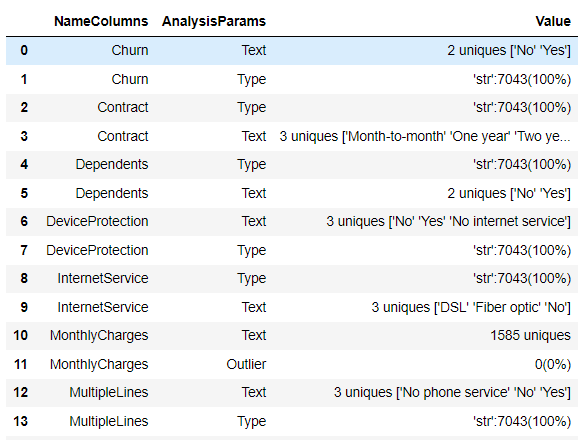
Посмотрим, как работает отдельно функция по анализу типов данных
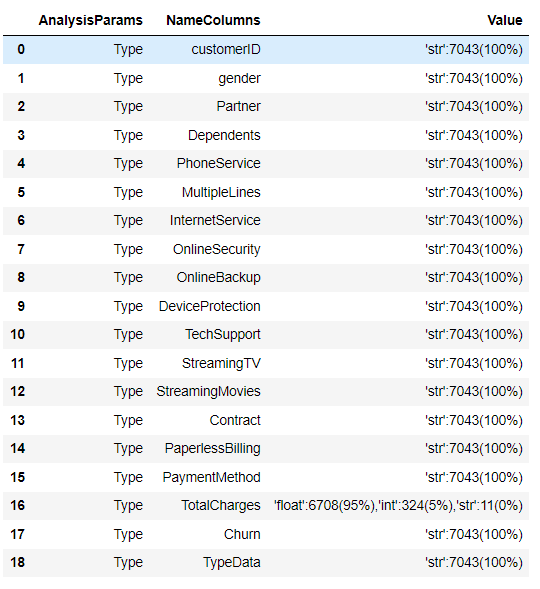
Заключение
Данное решение является для меня самым первым этапом анализа. Потенциальные проблемы или их отсутствие видны в таблицы. После этого можно начинать следующие шаги и сфокусироваться на требующих детальной разборки столбцах.
Повторюсь, если у вас есть предложения, что можно улучшить, добавить, скорректировать прошу в комментарии.
Как провести анализ данных в Python
Освойте анализ данных в Python с этим простым руководством: от основных библиотек до предобработки и визуализации данных!

Анализ данных в Python — это процесс изучения и обработки данных с помощью языка программирования Python для получения информации, обнаружения закономерностей или предсказания будущего поведения. В этом руководстве мы рассмотрим основные библиотеки и методы, необходимые для выполнения анализа данных в Python.
Основные библиотеки
Для анализа данных в Python существуют следующие ключевые библиотеки:
- NumPy — это библиотека для работы с массивами и матрицами. Она предоставляет множество функций для математических и статистических операций.
- Pandas — библиотека для работы с табличными данными (такими как Excel или SQL таблицы). Она предоставляет инструменты для очистки, агрегации и визуализации данных.
- Matplotlib и Seaborn — это библиотеки для построения графиков и визуализации данных.
Начало работы
Для начала установим необходимые библиотеки:
pip install numpy pandas matplotlib seaborn
Теперь импортируем их в наш Python-скрипт:
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Загрузка данных
Для анализа данных нам необходимо загрузить данные в формате CSV, Excel или SQL. В этом примере мы будем использовать данные о пассажирах Титаника в формате CSV:
data = pd.read_csv("titanic.csv") Посмотрим на первые несколько строк данных:
Предобработка данных
Перед анализом данных полезно провести предобработку, чтобы удалить пропущенные значения, исправить ошибки и преобразовать данные в удобный для анализа формат. Например, мы можем заполнить пропущенные значения возраста средним возрастом пассажиров:
data['Age'].fillna(data['Age'].mean(), inplace=True)
Также можно создать новый столбец с информацией о том, был ли пассажир один или с семьей:
data['Family'] = data['SibSp'] + data['Parch']
Анализ данных
Теперь, когда наши данные предобработаны, мы можем провести анализ данных. Например, можно исследовать связь между классом каюты и вероятностью выживания:
sns.barplot(x='Pclass', y='Survived', data=data) plt.show()
Также можно изучить распределение возрастов среди выживших и погибших пассажиров:
sns.histplot(data=data, x='Age', hue='Survived', kde=True) plt.show()
Выводы
В этом руководстве мы рассмотрели основные методы и библиотеки для анализа данных в Python. Надеемся, что это поможет вам в вашей работе со сложными наборами данных! 😊
Не забудьте обратить внимание на онлайн-школу, которая учит специалистов в сфере «Аналитика данных». Вставьте в текст спец.тег
Удачи вам в изучении анализа данных!